


 我的網誌
我的網誌
圖/AMD
AMD為CPU、GPU設計廠,推出MI300系列GPU對標輝達H100系列產品
AMD(Advanced Micro Devices,超微半導體)(AMD)是一家美國的半導體公司,主要生產和銷售處理器(CPU)、圖形處理器(顯卡、GPU)、晶片組、記憶體和其他相關產品,並提供相應的軟體和解決方案。
AMD在2023/6/13舉行AMD資料中心與AI首映會(AMD Data Center & AI Technology Premiere),推出了伺服器等級CPU EPYC、AI運算專用的MI300 GPU系列產品,以及宣布與被稱為AI界Github(管理、分享程式碼的平台)的Hugging Face合作,以期與輝達Nvidia(NVDA)的H100競爭。
AMD在原有的MI300A上,進一步推出獨立為GPU的MI300X晶片
AMD在今年初(2023/1/4)的CES大會推出資料中心APU(結合CPU與GPU的晶片),稱為MI300,其在AMD最近一次(2023/6/13)發布會中,調整名稱為MI300A,以與MI300系列的其他產品作出區隔。 MI300A內部包含了3個CPU與6個GPU晶片,而MI300X則是專門為了生成式AI、大型語言模型(Large Language Model,LLM)設計的晶片,將原本MI300A的3個CPU晶片,取代為另外2顆GPU晶片,因此MI300X中,有8個GPU晶片,但不包含CPU,邏輯晶片均採台積電5奈米製程,I/O等晶片則採其6奈米製程。
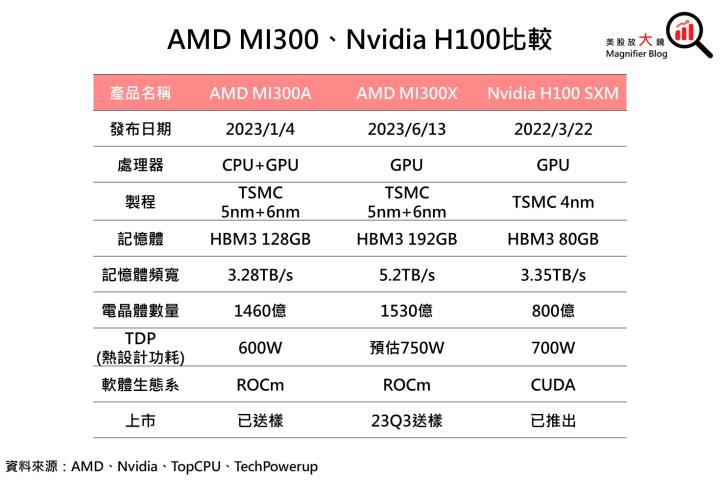
AMD MI300X的推出,無疑是想與Nvidia的H100一較高下。Nvidia H100早在2022/3/22即推出第一個版本,而後不斷推出規格升級與分化,現今最高規格的H100為H100 SXM,晶片採用台積電4奈米製程。
Nvidia H100的前身是A100,A100是微軟旗下OpenAI用於訓練ChatGPT模型的GPU,新一代的H100更是被期待可以以更高的性能應用在AI高效運算,搭配輝達專屬的CUDA生態系(Compute Unified Device Architecture,統一計算架構)開發大型語言模型等技術。
硬體規格上,AMD MI300系列優於Nvidia H100,算力也是
由上表進行比較,AMD的MI300系列比Nvidia H100還晚一年推出,也尚未進行量產,但AMD打擊競爭對手的策略即為堆高硬體規格,尤其是最新推出之MI300X記憶體高達192GB,比H100的80GB還要多出一倍有餘,記憶體頻寬也高出55%。價格部分,MI300系列使用台積電非最先進的製程,也有望將價格壓低。
除了硬體層面,在實際使用上,判斷GPU效能的指標為浮點運算能力FLOPS(Floating point operations per second),數字越大、效能越高,而FP64、FP32與FP16等術語,是工程師在開發不同應用時,在計算速度與精度之間取捨時,採用的不同規格。 簡單來看,依照FLOPS的數據來看,AMD MI250X的部分表現較H100佳(目前尚未有MI300系列之數據),H100雖然使用較先進的製程,但可能因晶片設計或架構因素使表現有差異,但輝達的H100在搭配上其Grace CPU晶片、形成Grace Hopper Superchip後,則可以有超越AMD的表現(將在下篇報告詳述)。

CUDA與ROCm均分別為Nvidia與AMD的GPU開發平台,使顯卡算力用於非圖像之平行運算
除了硬體規格外,針對使用者的軟體開發環境也同樣影響著購買意願。
Nvidia專攻GPU市場,鑽研顯卡工藝已久,輝達擁有的CUDA開發工具(Compute Unified Device Architecture,統一計算架構)為各大科技廠與開發者所使用,而AMD也有仿效CUDA所推出的ROCm(Radeon Open Compute platform),架構大致上是仿效CUDA所設計,目的就是為了讓輝達顯卡使用者便於移轉至使用AMD顯卡。
CUDA與ROCm的用途均為將原本用於運算與顯示圖像的顯卡,跳脫原有框架,進行高效平行運算,應用在人工智慧、醫學分析、加密運算等處。
相較之下,硬體、運算由MI300勝出,Nvidia掌握生態系與先行者優勢,主流地位不變,但AMD也並非完全劣勢
就硬體條件、運算能力層面表現而言,均由AMD的MI300表現後來居上,且超越H100一個層級;而輝達具有的優勢則仍然為早早透過CUDA建立的開發環境、完善的函式庫,使開發人員不願輕易拋棄建構已久且穩定的系統。
CMoney研究團隊認為在AMD推出MI300系列的AI加速器後,使其在資料中心等級GPU的未來更有發展機會,雖然現階段仍因CUDA這強大的護城河,而無法與輝達匹敵,但我們相信AMD在不斷針對ROCm的相容性優化與除錯、支援Pytorch(開源的機器學習框架、函式庫),以及與Hugging Face合作後,將有機會仿效其在x86 CPU市場與Intel蠶食市佔率的商業模式,吸引更多科技公司逐步採納AMD的GPU,制衡輝達在顯卡市場的獨佔地位。
輝達Nvidia在企業、消費級顯卡市場都具有絕對領先地位,AMD的最新產品仍需在正式推出後受市場考驗。CMoney研究團隊認為Nvidia為未來全球AI發展不可或缺的角色,AMD也具有巨大發展潛力,因此均看好兩家公司後市表現。
(延伸閱讀:【美股研究報告】超微AMD 23Q1營運落底,傳與微軟合作開發晶片,潛力可期!)
(延伸閱讀:【美股研究報告】超微AMD 22Q4 資料中心仍呈現成長,ChatGPT等AI各項應用崛起,AMD能分一杯羹?)
版權聲明
本文章之版權屬撰文者與 CMoney 全曜財經,未經許可嚴禁轉載,否則不排除訢諸法律途徑。
免責宣言
本網站所提供資訊僅供參考,並無任何推介買賣之意,投資人應自行承擔交易風險。



